TL;DR: 神经网络是模仿人脑的计算模型,通过多层节点处理数据实现识别和预测。用PyTorch构建简单网络分类手写数字只需几步:定义层、激活函数、训练优化。2026年硬件如苹果M4加速应用,但需注意数据需求和黑箱风险。从小模型起步,结合迁移学习高效实践。
神经网络基础原理
神经网络的核心是人工神经元,每个接收输入信号后通过权重、偏置和激活函数产生输出。公式为 y = f(∑w_i x_i + b),其中f引入非线性。ReLU函数 max(0, x) 在2021年成为主流,因为它计算快,避免梯度消失,提高GPU并行效率。到2026年,神经网络已集成日常设备,如苹果M系列芯片的神经引擎加速图像和语音任务。
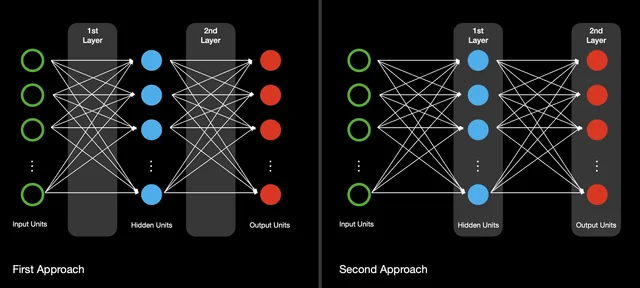
构建简单全连接网络
用PyTorch构建全连接网络分类MNIST手写数字,能直观理解神经网络原理。步骤包括导入库、定义模型、训练循环,10个epoch下准确率可达90%以上。
步骤1: 导入库和定义模型
导入torch和torch.nn。定义类Net继承nn.Module,在__init__中设置self.fc1 = nn.Linear(784, 128),self.fc2 = nn.Linear(128, 10)。forward函数:x = x.view(-1, 784),h = torch.relu(self.fc1(x)),return self.fc2(h)。
导入torch和torch.nn。定义类Net继承nn.Module,在__init__中设置self.fc1 = nn.Linear(784, 128),self.fc2 = nn.Linear(128, 10)。forward函数:x = x.view(-1, 784),h = torch.relu(self.fc1(x)),return self.fc2(h)。
步骤2: 准备数据和训练
加载MNIST数据集,标准化到[0,1]。用Adam优化器(lr=0.001)和交叉熵损失。批次64,10 epoch。若过拟合,加nn.Dropout(0.2)。2026年PyTorch 2.1优化训练至秒级。
加载MNIST数据集,标准化到[0,1]。用Adam优化器(lr=0.001)和交叉熵损失。批次64,10 epoch。若过拟合,加nn.Dropout(0.2)。2026年PyTorch 2.1优化训练至秒级。
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(784, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = x.view(-1, 784)
h = torch.relu(self.fc1(x))
return self.fc2(h)

苹果神经引擎硬件加速
神经网络硬件加速如苹果神经引擎从M1开始集成,到2026年M4芯片达38核,每秒38万亿次操作。用户反馈显示,它加速Final Cut Pro渲染至实时,Face ID准确率99.9%,但仅在AI任务中活跃,起价9000元人民币。
核方法 vs. 神经网络对比
核方法如SVM理论强大但复杂度O(n^3),不适合大数据;神经网络通过反向传播易并行,ReLU避免梯度问题。2012年AlexNet将ImageNet错误率降至15%,核方法已落后。
| 方面 | 核方法 (SVM) | 神经网络 |
|---|---|---|
| 训练复杂度 | O(n^3) | 易控制,GPU并行 |
| 准确率 (ImageNet) | 落后 | 95%以上 |
| 适用场景 | 小数据集 | 大数据图像 |
神经网络局限与风险
神经网络数据需求大,GPT-4级训练成本超1亿美元,黑箱性质需欧盟2024 AI法案解释报告。过拟合风险高,医疗假阳性率5%;能源消耗相当于跨太平洋航班。从小模型和迁移学习起步可缓解。
构建卷积神经网络 (CNN)
CNN适合图像分类,如CIFAR-10数据集准确率82%。用torchvision加载数据,定义卷积层和池化,SGD优化10 epoch。
步骤1: 数据加载
用transforms.Compose([ToTensor(), Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])。DataLoader shuffle=True。
用transforms.Compose([ToTensor(), Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])。DataLoader shuffle=True。
步骤2: 模型定义和训练
class CNN(nn.Module): conv1=nn.Conv2d(3,16,3,padding=1); pool=nn.MaxPool2d(2,2); fc1=nn.Linear(16*8*8,128)。forward中应用relu和pool。optim.SGD(lr=0.01),交叉熵损失,早停监控val loss。
class CNN(nn.Module): conv1=nn.Conv2d(3,16,3,padding=1); pool=nn.MaxPool2d(2,2); fc1=nn.Linear(16*8*8,128)。forward中应用relu和pool。optim.SGD(lr=0.01),交叉熵损失,早停监控val loss。
import torch.nn as nn
import torch.nn.functional as F
class CNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 16, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16*8*8, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = x.view(-1, 16*8*8)
x = F.relu(self.fc1(x))
return self.fc2(x)
常见问题解答
Q: 为什么ReLU激活函数在神经网络中流行?
A: ReLU计算速度快,避免梯度消失,提高训练效率,尤其适合GPU并行。到2021年,它已成为主流选择。
A: ReLU计算速度快,避免梯度消失,提高训练效率,尤其适合GPU并行。到2021年,它已成为主流选择。
Q: 神经网络训练需要多少数据?
A: 大型模型如GPT-4需数TB标注数据,成本超1亿美元。小团队可从小数据集和迁移学习起步。
A: 大型模型如GPT-4需数TB标注数据,成本超1亿美元。小团队可从小数据集和迁移学习起步。
Q: 苹果M4芯片的神经引擎值不值得买?
A: 如果从事AI图像或视频编辑,它加速渲染至实时,续航优秀,起价9000元;否则闲置无感。
A: 如果从事AI图像或视频编辑,它加速渲染至实时,续航优秀,起价9000元;否则闲置无感。
Q: 量子神经网络何时实用?
A: 2026年仍限于小规模,噪声和硬件落后,仅适用于药物设计模拟;经典GPU更成熟。
A: 2026年仍限于小规模,噪声和硬件落后,仅适用于药物设计模拟;经典GPU更成熟。
Q: 如何避免神经网络过拟合?
A: 添加nn.Dropout(0.2),监控val loss早停,使用迁移学习微调预训练模型。
A: 添加nn.Dropout(0.2),监控val loss早停,使用迁移学习微调预训练模型。
探索更多深度学习教程,或了解AI硬件趋势。