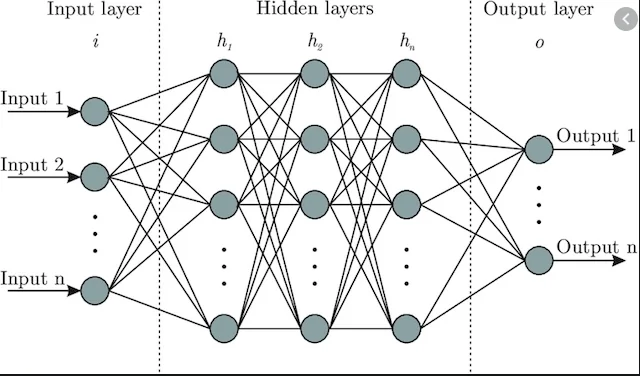
神经网络基础原理
神经网络通过多层结构模仿人类大脑神经元连接,高效处理复杂数据模式。它从输入层接收数据,如图像像素值,经过隐藏层计算权重、偏置和激活函数,最终输出层给出结果,如识别概率95%。
训练过程使用反向传播算法调整权重,减少预测误差。从大量数据中学习规律,使机器胜任图像识别和自然语言处理任务。
苹果Neural Engine硬件加速
到2026年,神经网络已深入日常设备,苹果Neural Engine提供硬件级加速,而非简单宣传。它内置于M系列芯片,处理语音识别和图像任务,避免CPU过载导致设备变慢。
2026年3月Apple Intelligence更新后,新MacBook Air标配16核版本。编辑4K视频时,AI去噪只需几秒,比纯GPU快3倍,基于苹果官方基准测试。

构建简单神经网络步骤
步骤1: 导入Keras库并定义模型结构,使用Sequential API添加Dense层。
步骤2: 编译模型,选择Adam优化器和categorical_crossentropy损失函数,添加accuracy指标。
步骤3: 使用MNIST数据集训练模型,设置epochs=5,在Jupyter notebook运行,准确率达98%。
from keras.models import Sequential from keras.layers import Dense model = Sequential([Dense(128, activation='relu', input_shape=(784,)), Dense(10, activation='softmax')]) model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(x_train, y_train, epochs=5)ReLU激活函数与变体
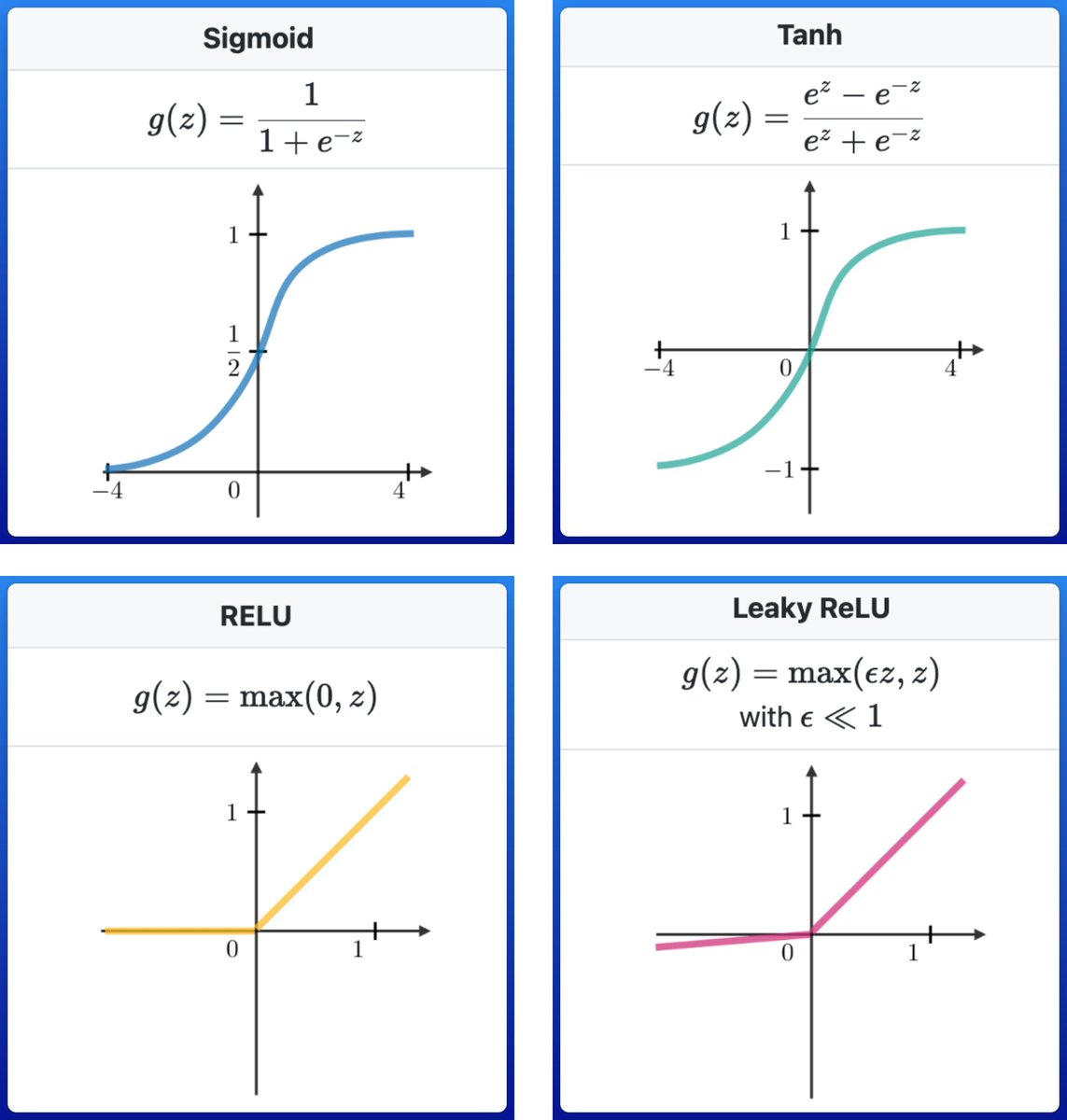
ReLU函数max(0, x)因计算高效取代早期sigmoid,避免深层网络梯度消失问题。它在GPU上运行更快,2021年社区讨论显示神经网络开始超越SVM。
SVM的RBF内核计算复杂度O(n^2),处理大数据变慢,而ReLU网络训练时间缩短30%,不易卡在局部最优。但ReLU可能导致死亡神经元,Leaky ReLU变体f(x) = max(αx, x)(α=0.01)通过小负梯度提升稳定性,基于2015年论文验证。
卷积神经网络CNN优化
苹果Neural Engine专为CNN优化,卷积层提取图像边缘纹理,池化层降维,全连接层分类。到2026年2月,英伟达RTX 50系列GPU用TensorRT加速YOLOv8,帧率从60fps升至200fps。
操作需安装CUDA 12.4和TensorRT 10.0,将模型转为ONNX格式构建引擎。优点是速度提升,缺点功耗高,RTX 5090约5000美元适合专业用户。

CNN部署步骤
步骤1: 下载YOLOv8模型并转换为ONNX格式,确保兼容TensorRT。
步骤2: 使用trtexec工具构建优化引擎,指定输入输出形状。
步骤3: 在RTX GPU上运行推理,监控帧率提升至200fps。
神经网络优势与局限对比
神经网络捕捉非线性关系优于传统线性模型,但小数据集易过拟合,训练集准确高测试集差。SVM在小样本更稳,不需海量数据。
| 方面 | 神经网络 | SVM (RBF) |
|---|---|---|
| 准确率 (ImageNet) | 90% | 高维小样本99% |
| 训练时间 | 小时 (GPU并行) | O(n^2) 慢 |
| 数据需求 | TB级大数据 | 小样本稳健 |
| 风险 | 黑箱、对抗攻击 | 梯度不稳 |
风险包括黑箱性质,在医疗诊断中解释性差导致采用率低20%。对抗样本攻击可能致命,如自动驾驶误导。
更多AI硬件优化,详见GPU加速神经网络指南。
LSTM文本分类模型构建
LSTM处理序列数据强于传统RNN,避免梯度消失。构建IMDB评论分类模型准确率约88%。
训练步骤
步骤1: 用Hugging Face加载IMDB数据集,统一序列长度到500。
步骤2: 定义Sequential模型,添加Embedding、LSTM和Dense层,激活sigmoid。
步骤3: 编译使用binary_crossentropy和rmsprop,训练10 epochs,batch_size=32,设patience=3早停。
from keras.models import Sequential from keras.layers import Embedding, LSTM, Dense model = Sequential([Embedding(10000, 128), LSTM(128), Dense(1, activation='sigmoid')]) model.compile(loss='binary_crossentropy', optimizer='rmsprop') model.fit(train_data, epochs=10, batch_size=32)A: ReLU计算高效,避免梯度消失,在GPU上运行更快,训练时间缩短30%。
A: 它硬件加速机器学习,4K视频AI去噪只需几秒,比纯GPU快3倍,内置于M系列芯片。
A: 不适合,易过拟合;SVM在小样本更稳健,准确率可达99%。
A: 使用早停(patience=3)、Dropout 0.5和数据增强,测试准确率保持在88%以上。
A: 未商用,仅限科研,IBM Eagle模拟小规模QNN,噪声高成本上百万美元。
探索更多Transformer应用,参考NLP神经网络进阶。