机器学习工程师与软件工程师的区别
在2026年,机器学习工程师专注模型训练和数据优化,而软件工程师负责将模型集成到生产系统中。这种分工让软件工程师成为幕后主力,将实验代码转化为可靠系统,尤其在中小型公司常见。
机器学习工程师多从事实验性工作,如用Python的Scikit-learn构建模型,调整参数提升准确率。但生产部署需处理可扩展性、实时性和故障恢复,这些依赖软件工程架构能力。结果,软件工程师常花时间修补数据管道稳定性。
拿电商推荐系统为例,机器学习工程师输出Jupyter Notebook,包含数据清洗和AUC分数0.85评估。但Notebook缺少面向对象结构和内存管理。软件工程师则测试生产环境表现,如每秒1000查询时的GPU稳定性,并用Docker和Kubernetes部署。
团队建议早用MLOps工具如MLflow跟踪实验,顺畅从原型到生产的过渡。

监督学习线性回归示例
监督学习用标注数据训练模型预测输出,线性回归是入门算法,用于预测连续值如房价,适合小数据集。
步骤1: 安装依赖
运行pip install scikit-learn,确保Python 3.11环境。检查数据无缺失值。
步骤2: 准备数据和训练
使用NumPy创建X和y数组,实例化LinearRegression模型并fit数据。用5折交叉验证评估,避免过拟合。
步骤3: 预测和保存
预测新值如model.predict([[5]])输出约10。保存模型:joblib.dump(model, 'model.pkl')。
import numpy as np
from sklearn.linear_model import LinearRegression
X = np.array([[1], [2], [3], [4]])
y = np.array([2, 4, 6, 8])
model = LinearRegression()
model.fit(X, y)
print(model.predict([[5]])) # 输出约10线性回归基于Scikit-learn 1.4版,几秒钟跑完。但对非线性问题,随机森林更好,能降低方差。风险:噪声数据导致泛化差,预测偏差。
角色分工对比表
| 角色 | 重点任务 | 工具示例 |
|---|---|---|
| 机器学习工程师 | 模型训练、数据优化 | Scikit-learn, Jupyter |
| 软件工程师 | 生产集成、部署监控 | Docker, Kubernetes |
硬件选择:MacBook Pro M3在机器学习中的优势
2024年Reddit讨论显示,MacBook Pro M3芯片适合中型模型训练,用PyTorch MPS后端,BERT微调时间缩短20%,电池续航18小时,便于移动开发。
M3神经引擎加速矩阵运算,生态兼容Homebrew简化TensorFlow安装。相比Windows机(续航4-6小时),Mac便携性强,2026年入门版约8000元人民币。但大型LLM训练时,MPS不支持所有CUDA操作,速度慢3-5倍。
边界:分布式训练用Linux服务器或AWS EC2更可靠。Apple Metal落后NVIDIA CUDA,后者用TensorRT优化到毫秒级延迟。
MacBook适合原型开发,如咖啡店测试小数据集。但企业部署需Docker确保跨平台兼容。风险:忽略兼容性导致部署失败。
 深入了解PyTorch在Mac上的优化技巧
深入了解PyTorch在Mac上的优化技巧
机器学习系统设计四步指南
系统设计平衡业务和工程,优先可观测性和容错。依据欧盟GDPR 2026更新,需全覆盖日志,否则合规问题导致下线。
步骤1: 定义问题
如欺诈检测系统,目标召回率>95%。评估ROI,如果准确率提升<10%,别用ML。
步骤2: 数据管道
用Apache Kafka摄入实时数据,Spark清洗,延迟<1秒。确保数据质量,避免偏差导致15%错误率。
步骤3: 模型训练
XGBoost处理表格数据,在TPU v5训练,用Alibi Detect监控drift。用Locust压测1000 QPS。
步骤4: 部署监控
Seldon Core serving模型,Prometheus追踪latency和error rate。云成本每月可达5000美元,从POC起步。风险:高负载崩溃率升10%。
PyTorch CNN图像分类器构建示例
PyTorch用于构建CNN图像分类器,卷积层提取特征,全连接层分类,测试accuracy >70%。
步骤1: 导入和加载数据
import torch; import torchvision。加载CIFAR-10数据集,用transforms.Compose处理。
步骤2: 定义模型
class Net(nn.Module): 添加Conv2d、pool和fc层。
步骤3: 训练循环
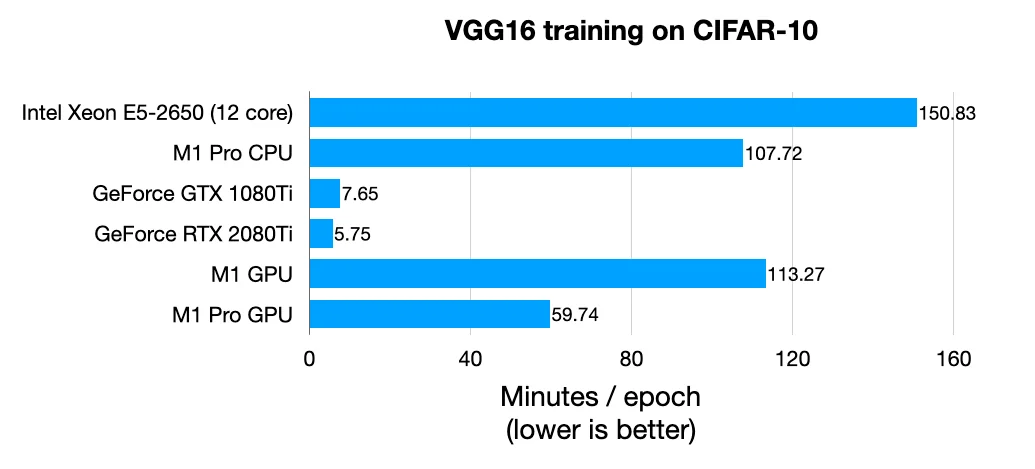
for epoch in range(10): optimizer.zero_grad(); loss.backward(); optimizer.step()。batch_size=64,每epoch 2分钟。在M3 Mac上用num_workers=4加速,但监控过热。
import torch
import torchvision.transforms as transforms
from torchvision import datasets
transforms = transforms.Compose([transforms.ToTensor()])
trainset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transforms)
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = torch.nn.Conv2d(3, 6, 5)
# 添加更多层...
# 训练循环
for epoch in range(10):
for inputs, labels in trainloader:
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()风险:过热导致中断。用Hugging Face Transformers微调BERT,生产需A/B测试。
FAQ
怎么选择机器学习硬件?
对于中型模型,MacBook Pro M3是首选,训练速度快20%,续航18小时。但大型LLM需NVIDIA GPU服务器。
为什么机器学习不适合所有场景?
数据少于1000样本时,规则-based系统更可靠,避免泛化差。医疗诊断偏差可达15%,ROI提升<10%不值得用ML。
软件工程师如何转型机器学习?
通过Coursera Andrew Ng课程,3个月上手模型调优。学AutoML API如Google Vertex AI,并在项目中实践生产部署。
机器学习系统设计的关键风险是什么?
忽略监控导致模型drift,准确率降20%。需用Prometheus追踪,并遵守GDPR日志要求,避免合规罚款4%营收。
哪个工具适合初学者入门监督学习?
Scikit-learn是最简单,线性回归几秒跑完。结合Jupyter Notebook实验,快速验证AUC分数如0.85。