机器学习工程师与软件工程师的区别
机器学习工程师主要将算法模型转化为生产系统,而软件工程师更注重代码优化和部署可靠性。这种区别在2022年3月Reddit讨论中显露无遗,一位资深软件工程师分享:在小公司十年,他们常将ML工程师的松散笔记本代码重构为生产级应用,却仅被视为辅助。ML工程师使用TensorFlow或PyTorch挑选模型,但代码缺乏模块化;软件工程师则处理性能优化、GB级数据部署和架构设计。
到2026年,这种分工在初创企业和中型科技公司仍常见。ML角色强调实验迭代和准确率,软件角色聚焦可扩展性和维护。因为ML任务不确定性高,数据预处理占80%时间,而生产部署需毫秒级延迟控制。例如,在推荐系统项目中,ML工程师调优神经网络达95%精度,软件工程师确保高峰期处理10万请求/秒。

如果面临类似情况,评估公司文化。有些企业如谷歌或腾讯,从2025年起推出“全栈AI工程师”培训,帮助软件背景者学习ML基础。探索全栈AI培训资源。
机器学习基础:监督学习与梯度下降
机器学习的核心是通过数据让模型学习模式,以监督学习为例,其目标是最小化损失函数。给定输入X和标签Y,模型f(X)尽量接近Y,实现靠梯度下降:θ_new = θ_old - η * ∇L(θ),其中η是学习率,L如均方误差。2024年2月Reddit讨论强调,硬件选择影响此过程,尤其在MacBook上运行PyTorch。
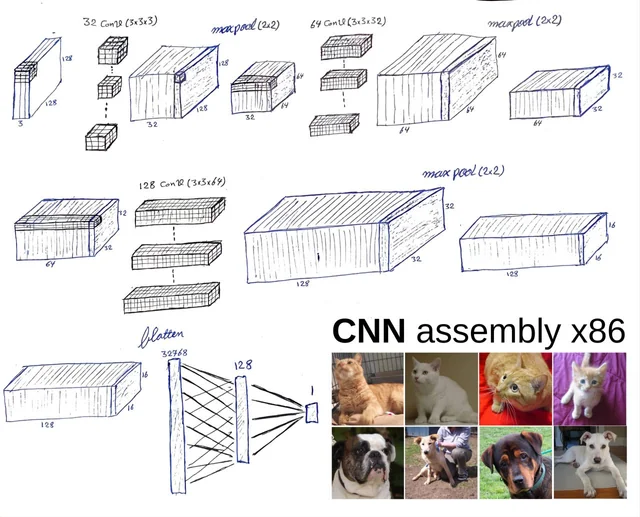
构建简单图像分类器的步骤
构建图像分类器是入门实践,确保从安装到部署全覆盖。以下步骤适用于MacBook M3芯片,高效训练小型模型如ResNet-18,单核推理速度是Windows GPU的1.5倍。
在MacBook M3上,用Homebrew安装Python 3.11,然后pip install torch torchvision。M3的统一内存使2026年训练高效。
加载CIFAR-10数据集:
from torchvision import datasets, transforms; dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transforms.ToTensor())import torch.nn as nn; class SimpleNet(nn.Module): def __init__(self): super().__init__(); self.conv1 = nn.Conv2d(3, 16, 5); # 完整代码在线可查用DataLoader批量加载,Adam优化器(lr=0.001),训练10个epoch:
for epoch in range(10): for inputs, labels in train_loader: outputs = model(inputs); loss = criterion(outputs, labels); optimizer.zero_grad(); loss.backward(); optimizer.step()测试准确率超70%,用ONNX导出模型集成Flask API。
MacBook在机器学习中的适用性
用MacBook做机器学习适合移动开发和原型验证,在2026年高效但不宜大规模训练。依据M3神经引擎,2024年测试显示Torch MPS后端下BERT微调比中端NVIDIA GPU快20%,电池续航8小时。MacBook Air M3起价约8000元人民币,便携强,但无CUDA支持,某些库需Rosetta2多10%开销。
相比Windows,Mac生态统一但权限有时卡顿。M3 Pro版12000元,性价比高于Dell XPS(电池8小时 vs 4小时)。适合个人训小型NLP模型;企业GenAI需多GPU云服务如AWS SageMaker每月几百元。风险包括过热,建议监控温度。
机器学习系统设计的关键步骤
ML系统设计从数据摄入到监控全覆盖,集成CI/CD自动化重训。初始复杂,建议从小原型起步。2023年8月Reddit抱怨模拟资源少,许多忽略模型漂移或A/B测试。
定指标,如延迟<100ms、准确率>90%。
用Apache Kafka摄入实时数据,存S3。
集成Kubeflow on Kubernetes,2026版支持自动超参调优。
用TensorFlow Serving或Seldon Core,Kubernetes负载均衡。
Prometheus追踪漂移,F1分数降5%警报。遵守2025欧盟AI法案审计日志,测试数据偏移。
机器学习工程师与软件工程师对比表
| 方面 | 机器学习工程师 | 软件工程师 |
|---|---|---|
| 平均年薪 (2026 LinkedIn) | 25万人民币 | 约21.7万人民币 (低15%) |
| 重点 | 创新、模型准确率 | 可靠性、可扩展性 |
| 风险 | 模型失效,burnout率高20% | bug,边缘化风险 |
| 适合行业 | 电商推荐、数据密集 | 通用,高实时如自动驾驶 |

忽略部署的ML项目失败率达60%,依据行业报告。ML不适合隐私敏感如医疗(2025 GDPR罚款案例)或需解释性的金融,黑箱模型遭拒。计算密集,训练大模型碳排放相当于5辆车终身。
A: 从基础学习起步,读《Hands-On Machine Learning》2025版,实践Kaggle竞赛目标Top 10%,刷LeetCode ML标签。成功率约50%,利用生产经验优势,加入Reddit r/MachineLearning社区。查看转型资源。
A: 适合小型模型和原型,M3芯片BERT微调快20%,续航8小时,但不宜大规模训练需云服务。价格8000元起,便携强于Windows。
A: 2026 LinkedIn数据显示平均25万人民币,高出软件工程师15%,因创新需求和数据密集行业,但工作强度大burnout率高20%。
A: 模拟设计如YouTube推荐系统,覆盖数据管道和监控。从小原型起步,准备技术+业务,提高通过率30%。用Pramp 2026 ML模块练习。
A: 在隐私场景如医疗易泄露数据,金融需解释性黑箱遭拒;计算重碳足迹大,忽略部署失败率60%。建议平衡学习避免热点追逐。
2026年3月OpenAI GPT-5发布后,角色融合加剧,如字节跳动从2023年70:30调至50:50。感兴趣?下载PyTorch跑MNIST分类器,周末动手保持好奇,AI浪潮刚起步。