李宏毅课程概述
李宏毅的机器学习课程以生动讲解著称,帮助初学者快速上手核心概念。通过宝可梦Go等日常生活例子,它将抽象数学和算法拉近现实,避免初学者茫然无措。
作为台湾大学电气工程系副教授,李宏毅的课程从2010年代中期流传开来,到2026年已成为AI从业者标准起点。2020年11月25日,Datawhale开源组发布《LeeDeepRL-Notes》,覆盖从马尔可夫决策过程到PPO算法的强化学习笔记和代码,包括习题和项目验证理解。2025年春季版新增扩散模型和多模态学习模块,对应ChatGPT等大模型流行。他的PPT简洁配动画,教学风格亲切。
为什么选择作为起点
它在理论与实践间平衡,避免初学者迷失数学细节。从监督、无监督和强化学习基础入手,第一堂课用简单分类任务说明神经网络预测。即使数学背景薄弱,也能跟上。缺点是对专家太基础,但对大多数人是理想桥梁。建议从2021年3月6日上线的2021春季课程开始,免费下载视频和PPT,搭配笔记两周打牢基础。
深度学习核心内容
李宏毅注重直观解释深度学习。以CNN为例,他先展示图像识别任务:用CNN辨别宝可梦类型,从像素提取特征到输出结果。
深度学习实践步骤
CNN通过滑动窗口捕捉局部特征,池化层降低维度。2026年更新对比Vision Transformer,自注意力机制并行处理全局依赖,更高效。
import torch
import torch.nn as nn
import torchvision
from torchvision import datasets, transforms
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 3, padding=1)
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(2, 2)
self.fc = nn.Linear(16 * 16 * 16, 10) # For CIFAR-10
def forward(self, x):
x = self.pool(self.relu(self.conv1(x)))
x = x.view(-1, 16 * 16 * 16)
x = self.fc(x)
return x
# Training loop example
model = SimpleCNN()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# Add data loaders and train
强化学习核心内容
强化学习是课程亮点,将奖励机制从抽象转为可操作,用Atari游戏演示。从Q-learning开始,解释状态-动作-奖励的马尔可夫过程:代理试错最大化累积奖励。
《LeeDeepRL-Notes》推导Q-learning公式:Q(s,a) ← Q(s,a) + α [r + γ max Q(s',a') - Q(s,a)],α=0.1,γ=0.9。早期DQN计算密集,2026年用GPU加速,但初学者一周内难训高手。
与其他课程对比
李宏毅课程以中文表达和趣味案例脱颖而出,比吴恩达的Coursera更适合亚洲学习者。吴恩达偏工程,2025年豆瓣讨论指其Octave作业门槛高,而李宏毅用Python现代。
| 方面 | 李宏毅课程 | 吴恩达课程 |
|---|---|---|
| 价格 | 免费 | 49美元/月 |
| 时长 | 每节1小时 | 系统但有时拖沓 |
| 例子 | 动漫趣味 | 工程应用 |
| 适合人群 | 中文初学者 | 求证书职场 |
2026年自学者多选李宏毅对接PyTorch生态。若追求证书,吴恩达更合适。两者可靠,无明显风险。
深度学习PyTorch进阶教程课程局限与扩展
GAN讲解有趣但推导不详尽,2021版只用两节课过Wasserstein GAN,实际训练模式崩溃率可达30%,需手动调参。不适合NeurIPS论文目标,需补充2026年量子机器学习等前沿。
无监督学习示例
无监督学习强调聚类和降维价值。K-means简单高效,但需预设K:迭代分配样本到最近中心,直至收敛。用Iris数据集,sklearn.cluster.KMeans(n_clusters=3),标准化后fit,PCA可视化2D。肘部法选K,准确率92%。
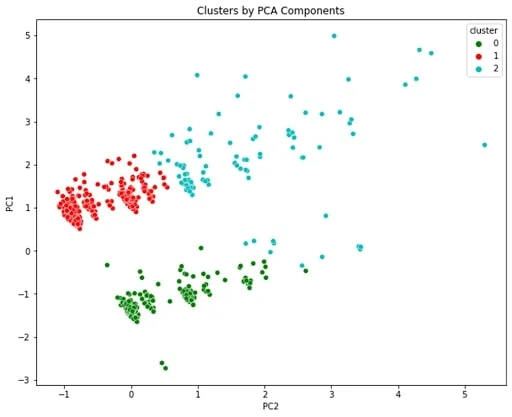
高维图像需先提取特征。不适非凸簇,DBSCAN更好却参数敏感。
AI伦理与社区影响
2026年更新加AI伦理:数据集偏差致歧视,用adversarial debiasing。AIF360评估demographic parity,招聘模型差距降15%。社区影响力大,Bilibili播放超千万,2025年豆瓣70%推荐给初学者。
AI伦理最佳实践常见问题解答
A: 从NTU官网下载2021春季视频和PPT,第一堂课学习监督学习基础,结合PyTorch代码实践,一个月见进步。
A: 它用趣味例子如宝可梦避免数学枯燥,平衡理论实践,两周打牢基础,即使背景薄弱也能跟上。
A: 初学者一周内难训高手,但通过OpenAI Gym实践1000 episodes,一周可理解Q-learning核心。
A: 李宏毅免费且中文友好适合自学,吴恩达工程强求证书更好;2026年自学者多选李宏毅。
A: 新增扩散模型、多模态学习和AI伦理模块,对应ChatGPT流行和偏差问题,视频4K加quiz。